Projects: Learning to See
- We increase the autonomy capabilities of underwater robotic platforms.
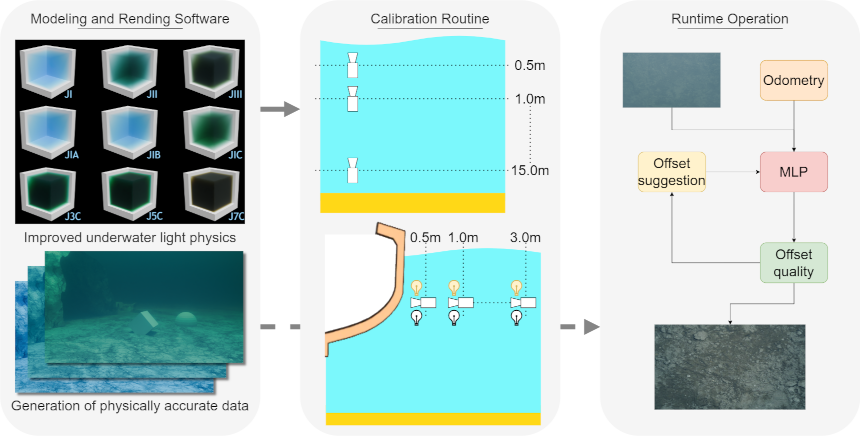
- We improve simulation of underwater imagery within the Blender modeling software, including more accurate light behaviour in water, and models of the oceans.
- We introduce a method for in-situ water column property estimation using a monocular camera and adjustable illumination.
- We design a framework providing online guidance suggestions to maintain high-quality data collection and maximise visual coverage in a broad range of water conditions.
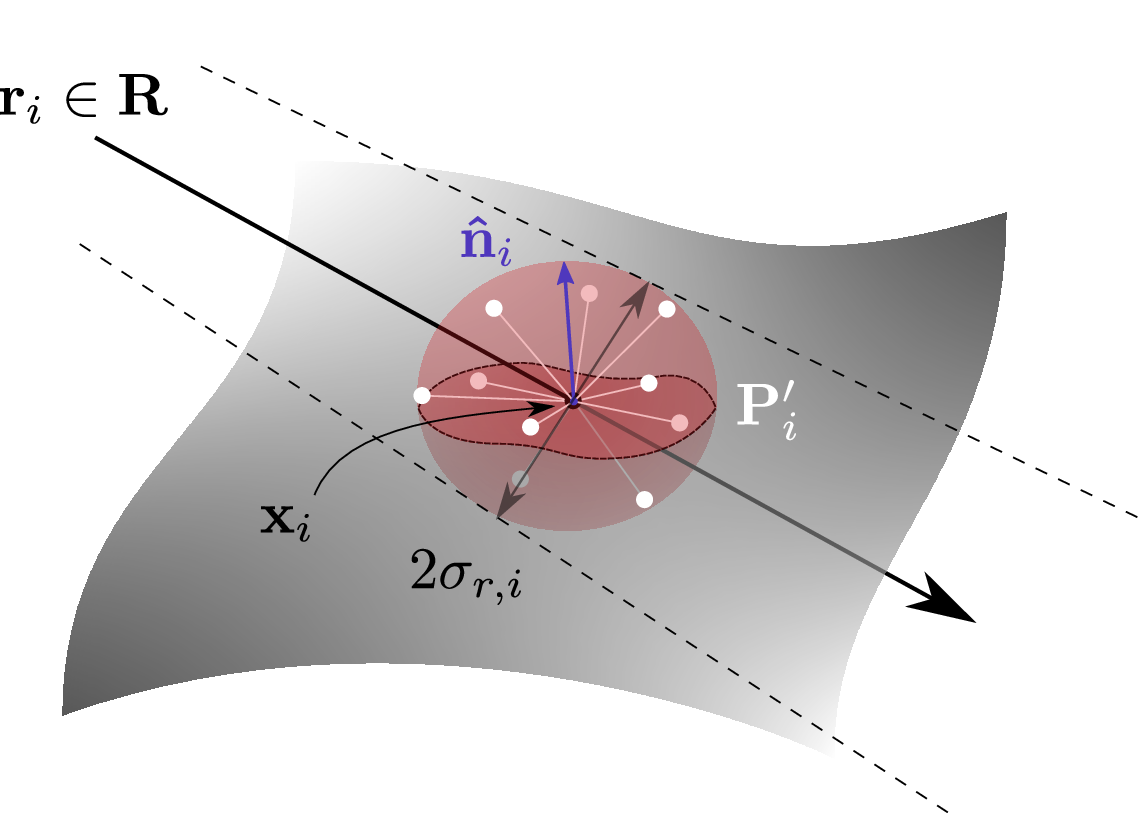
- Surface light field inspired regularisation to improve geometric fidelity of NeRF-based representations
- We propose a second sampling of the representation to regularise local appearance and geometry at surfaces in the scene
- Applicable to future NeRF based models leveraging reflection parameterisation
- An effective light field segmentation method
- Combines epipolar constraints with the rich semantics learned by the pretrained SAM 2 foundation model for cross-view mask matching
- Produces results of the same quality as the Segment Anything 2 (SAM 2) video tracking baseline, while being 7 times faster
- Can be inferenced in real-time for autonomous driving problems such as object pose tracking
- A learned feature detector and descriptor for bursts of images
- Noise-tolerant features outperform state of the art in low light
- Enables 3D reconstruction from drone imagery in millilux conditions
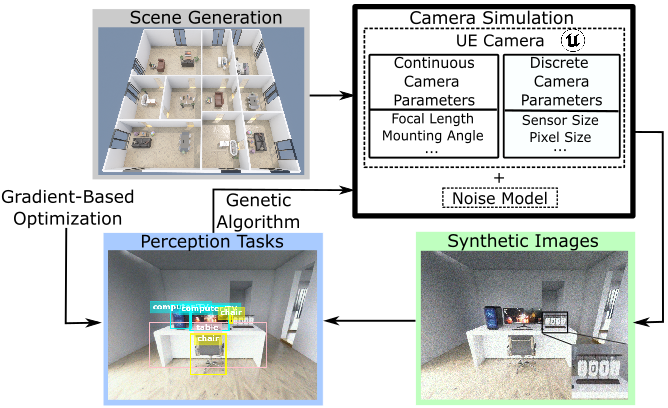
- An end-to-end camera design method that co-designs cameras with perception tasks
- We combine derivative-free and gradient-based optimizers and support continuous, discrete, and categorical parameters
- A camera simulation including virtual environments and a physics-based noise model
- Key step in simplifying the process of designing cameras for robots
- RectConv adapts existing pretrained CNNs to work with fisheye images
- Requires no additional data or training
- Operates directly on the native fisheye image as captured from the camera
- Works with multiple network architectures and tasks
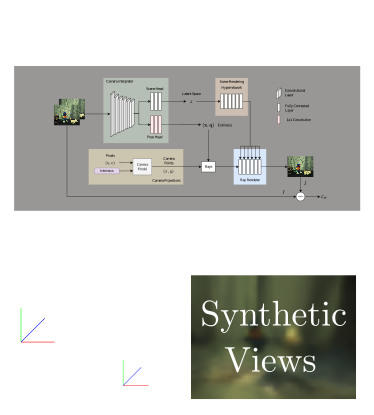
- Automatically interpreting new cameras by jointly learning novel view sythesis, odometry, and a camera model
- A hypernetwork allows training with a wealth of existing cameras and datasets
- A semi-supervised light field network adapts to newly introduced cameras
- This work is a key step to automated integration of emerging camera technologies
- Jointly learning to super-resolve and label improves performance at both tasks
- Adversarial training enforces perceptual realism
- A feature loss forces semantic accuracy
- Demonstration on aerial imagery for remote sensing
- Unsupervised learning of odometry and depth from sparse 4D light fields
- Encoding sparse LFs for consumption by 2D CNNs for odometry and shape estimation
- Toward unsupervised interpretation of general LF cameras and new imaging devices
- Fast classification of visually similar objects using multiplexed illumination
- Using light stage capture and rendering to drive optimization of multiplexing codes
- Outperforms naive and conventional multiplexing patterns in accuracy and speed